AI adoption is increasing at an unprecedented rate in the world. And at the core of AI are AI agents. Almost every industry in the world is adopting AI agents whether its finance, healthcare, HR, banking, automobile, supply chain or any other.
Many companies have already implemented AI agents into their systems and can see positive changes in terms of enhanced employee productivity, increase in sales, improved customer satisfaction rate, and many more.
However, one common question businesses often come across is how to measure AI agent success? It’s good that you have integrated AI into your processes but how do you actually measure if it’s success in your business, what are the metrics? Read this block to learn how to measure an AI agent’s success.
Why Measuring AI Agent Success Matters?
Onboarding an AI agent without clear goals is like going somewhere without a map. With AI investments growing machinery organisations must quantify if these AI agents are actually delivering value in terms of business outcomes and customer experience. Measuring outcomes help shareholders:
- Ensure the AI tools meet its goals efficiently and effectively
- Identify weak areas or the ones need retraining
- Optimize resources efficiently and save on operational costs
- Improves user satisfaction and enhance engagement
- Justify return on investment and make strategic decisions
Clear metrics turn AI agents into trusted tools that help to outrank the competitors.
What does success mean for AI agents?
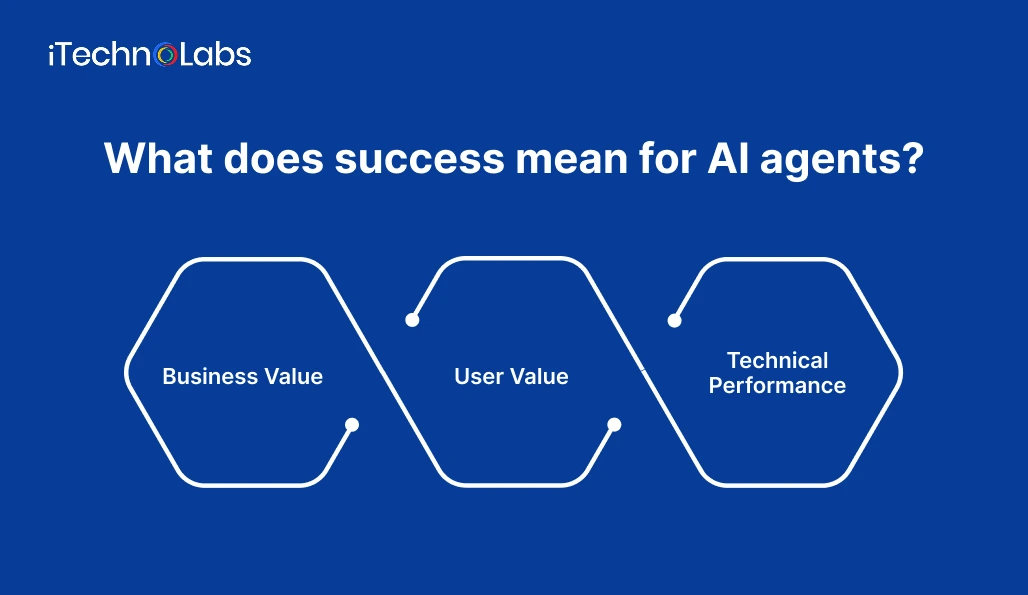
Success is not the same for every tool. An AI tool built to save time for HR professionals as a different mission than the one made for artists and writers. Based on every use case the success metrics will differ. To evaluate the success of AI agents its important to define what success means from different point of views:
-
Business Value
Is the agent saving time? Improving team members’ productivity? Helping to convert more leads?
Here, metrics are focused on measurable outcomes – productivity improvement per employee, lead generation per month, etc.
-
User Value
Are people actually using the AI agent? Do they find it accurate, useful, and reliable for daily usage? This perspective includes satisfaction scores such as CSAT, user attention rates and drop-off rates. For internal AI agents, one can also consider the time it saves for team members.
-
Technical Performance
Is the AI agent accurate and reliable? Is it escalated anytime or does it maintain the context within conversations? This consists of metrics like fallback rates, uptime, and tool execution success. Especially in a high-stakes environment, technical expertise is a factor of success in itself.
Following is how the metrics of success shift from one use case to another:
| Sector | Primary users | Key success metrics |
| Customer support | External customers | CSAT, response time, NPS, resolution rate, fallback rate |
| Internal HR | Employees | Reuse rate, accuracy, time saved per query, deflection rate |
| Sales | Sales representative | Adoption rate, lead response time, CRM updates completed |
| General purpose | Mixed (internal/external) | Escalation behaviour, tool usage success |
| Task-specific | Operational teams | Task completion rate, process acceleration time, error reduction |
Suggested Article: AI Agent in Customer Service
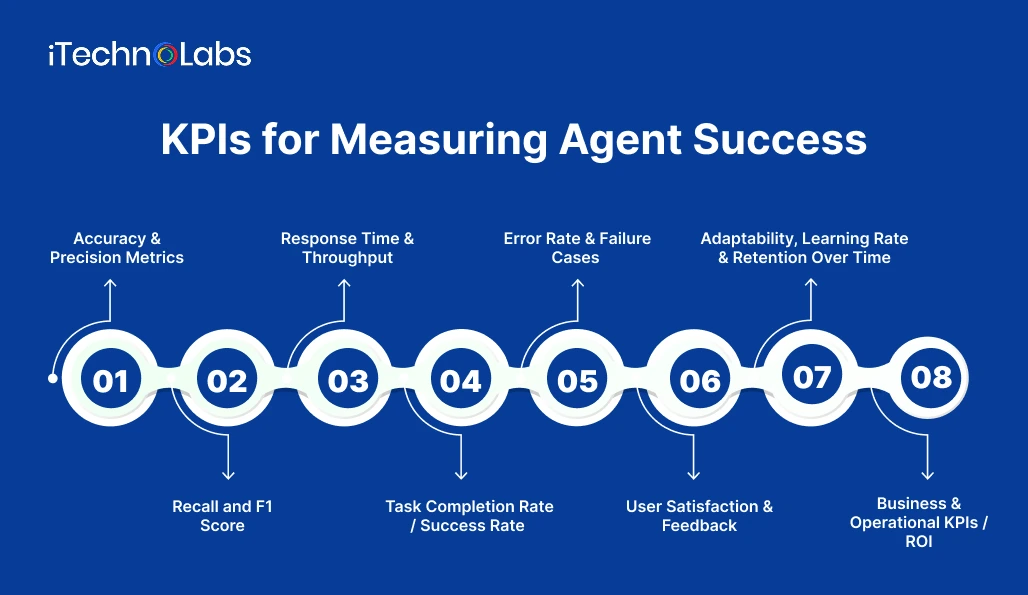
KPIs for Measuring Agent Success
To assess whether an AI agent is achieving its intended goals one must define Key Performance Indicators (KPIs) that capture technical efficacy, business impact, and user experience. KPIs translate abstract objectives into measurable signals. As observed in recent studies, success rates tend to decline as task complexity increases, so it’s crucial to pick KPIs that reflect both simple tasks and growth under heavier loads. Moreover, ROI, adaptability, error handling, and customer or user satisfaction are equally essential. Together these metrics help guide decisions about deployment, scaling, and improvement.
1. Accuracy & Precision Metrics
Measure the rate at which the agent’s outputs are correct (accuracy) and the proportion of its positive predictions or detections that are true (precision). A high accuracy but low precision means many false positives; high precision but low accuracy means many true items are missed. Combining both via metrics like the F1-score helps balance trade-offs. In domains like medical diagnosis, fraud detection, or NLP intent recognition these matter a lot. These metrics help quantify reliability.
2. Recall and F1 Score
Recall (sensitivity) measures how many real instances the agent captures vs. those it misses. F1 score balances recall and precision in one value. Recall is critical when missing something has a high cost (e.g. disease, fraud). F1 gives a single measurement useful for comparing models when data is imbalanced or error types carry different weights. Tracking improvements in recall or F1 over time shows learning, but they must be interpreted in context.
3. Response Time & Throughput
Response time is how quickly an agent responds to a request or completes a sub-task. Throughput is the volume of tasks processed over time. An agent may be very accurate but slow, which limits usability and scalability. These metrics are particularly important in real-time applications or high traffic environments (e.g., customer service). Monitoring both ensures the agent isn’t only correct but also efficient. Performance under load is a critical test.
4. Task Completion Rate / Success Rate
The proportion of tasks the agent fully completes without needing human intervention. That includes subtasks: whether the agent can follow through all stages, not just the first action. Success rate often drops for longer or more complex tasks. AIMultiple’s benchmarks show agents perform better on tasks requiring ~30-40 minutes of human time and diminish beyond that. Setting target task lengths and measuring over those helps tune what kinds of tasks an agent should handle.
5. Error Rate & Failure Cases
How often the agent fails — wrong response, confusion, inability to complete, or produces undesirable side-effects. Analysis of failure modes reveals blind spots: data drift, edge cases, domain gaps. Tracking where the agent errs, and quantifying error frequency, helps diagnose and improve stability, safety, and trustworthiness. Especially in regulated domains, error rate is as important as accuracy or recall.
6. User Satisfaction & Feedback
Metrics like CSAT (Customer Satisfaction), Net Promoter Score (NPS), user ratings, qualitative feedback. They capture whether users perceive the agent as helpful, usable, trustworthy. High technical performance means little if users are frustrated or drop off. User feedback identifies unanticipated issues, UX problems, or misalignment between what agent delivers vs. user expectations. Regularly surveying user experiences helps monitor adoption and reveal areas for improvement.
7. Adaptability, Learning Rate & Retention Over Time
How quickly and how well the agent improves with new data, feedback, or changing environments. For example, does its accuracy increase, error rate drop, or task success improve with time or after retraining? Also retention: whether the agent maintains performance as input distributions shift. An agent built for static tasks may perform poorly in dynamic settings. Measuring improvement over time ensures the model stays relevant.
8. Business & Operational KPIs / ROI
These tie agent outputs to business outcomes. Cost savings (e.g., reduced human hours), revenue uplift, time saved per employee, process acceleration, cost per query, and operational efficiencies. Also, adoption rate: how many users or transactions use the agent vs manual alternative. For decision-makers, these metrics justify investment. AIMultiple shows firms that measure ROI rigorously outperform those relying purely on technical or anecdotal success. Business metrics ensure alignment with strategy.
Beyond the Metrics: What About Trust and Adoption?
One can measure the AI agent’s success in terms of metrics like accuracy scores, deflection rate and many more. However, this doesn’t always mean that people also want to use your agent or trust it.
The success of an AI agent not only depends on its technical performance but also on whether people trust it or not. Even the best AI agents may fail if people are not finding it useful or if it has a complex user interface.
Therefore, there are some other factors that need to be considered while evaluating an AI agent success which are as follows:
-
Consistency and Explainability
Trust is built when the tool is reliable. People would love to choose your agent if it’s consistent and gives predicted answers every time. In highly regulated domains like finance, healthcare, and HR this often becomes a necessity rather than an add on. Hallucinations and confused answers don’t just erase trust but they also introduce business risk.
Good AI agents are the ones that:
- Provide answers backed by relevant citations and sources
- Always stay within their scope of knowledge
- Clarify when they are not sure about something
-
Privacy and Safe Data Handling
To measure AI agent success, you must ensure the system handles data securely and transparently. Key metrics include data boundary enforcement, access permissions, redaction of personal info, and logs of what data was used and why. If user trust drops because of ambiguity around data usage, even high accuracy or speed won’t matter. Metrics should capture whether sensitive information is handled properly and whether users feel confident about how their private data is treated.
-
Feedback Loops and Iteration
Feedback loops are core to improving an AI agent. To measure AI agent success, track user ratings (thumbs-up/down), free-text comments, surveys, and how often feedback leads to concrete model or workflow changes. Monitor trends in usability, errors, and adoption after each iteration. Iterate based on evidence not assumption. Success means the agent evolves—with gradual improvements in trust, user satisfaction, accuracy, and value delivered.
Important Article: Top AI Development Tools and Frameworks Every Business Should Know
Conclusion
Agents are not something that you can set and forget. They need consistent monitoring to ensure they are delivering the value they are integrated for. One should start measuring the performance of an AI agent from the beginning itself instead of waiting for the situation to escalate. The earlier you will start monitoring, the sooner you will understand how your AI agent is working. By using the above mentioned KPIs you can ensure your AI agent is working perfectly aligning with your business goals. To measure your AI agent success you can partner with a reliable AI development company. iTechnolabs is a renowned name in the world of AI development sector. With over 9 years of experience and 230+ members, 840+ projects delivered successfully, iTechnolabs is the right choice for you when it comes to AI agent development or measuring its success. Contact us now to onboard AI agents or to find out loopholes in your AI agent and correct them to outrank your competitors.
FAQs
1. How to measure AI agent performance?
There are many ways to measure the performance of an AI agent. However, the most popular KPIs to measure an AI agent’s success are accuracy, response time, task completion rate, error rate, and user satisfaction rate.
2. How to measure success in AI?
Following are some of the most common methods to measure the success of an AI model:
- User satisfaction rate
- Response time
- Accuracy
- Task completion rate
- Error rate
3. How to measure agent performance?
There are many ways to measure an AI agent’s performance like:
- Abandon rate
- Average handle time
- Customer satisfaction
- Cost
- Service level